

作为一名码农,想必都知道Hello World,什么,你竟然不知道?哦,那你可能不是码农,抬走,下一个。言归正传,在码农界,存在一首打油诗,我带大家一道欣赏。

手持两把锟斤拷,口中疾呼烫烫烫。脚踏千朵屯屯屯,笑看万物锘锘锘。

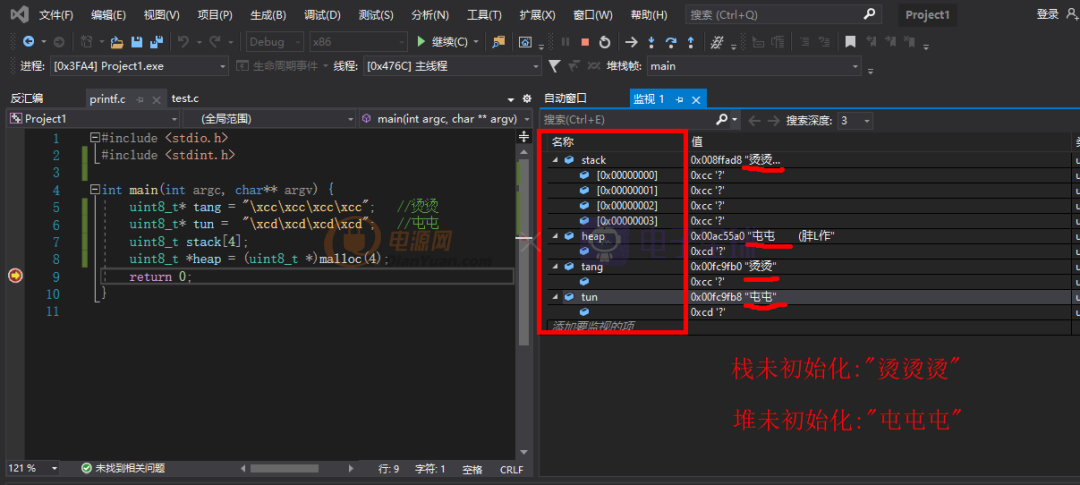
如果非要给一个诗名,我希望是“码到成功”。在此说一下“烫烫烫”以及“屯屯屯”的梗以及原理。在Visual Studio中,未初始化的栈空间默认值是0xcc,未初始化的堆空间默认值是0xcd。而在GB2312编码中,0xCCCC对应的中文是“烫”。0xCDCD对应的中文是“屯”。说的太苍白,那就来看一个示例:
#include <stdio.h>
#include <stdint.h>
int main(int argc, char** argv) {
uint8_t* tang = "\xcc\xcc\xcc\xcc"; //烫烫
uint8_t* tun = "\xcd\xcd\xcd\xcd"; //屯屯
uint8_t stack[4];
uint8_t *heap = (uint8_t *)malloc(4);
return 0;
}可以在观察窗口中看到定义的未初始化的堆栈数据值。一个是栈未初始化,一个是堆未初始化,所有就有了“烫烫烫...”、“屯屯屯...”
再说锟斤拷与锘之前,还是先回顾那首打油诗
手持两把锟斤拷,
口中疾呼烫烫烫。
脚踏千朵屯屯屯,
笑看万物锘锘锘。
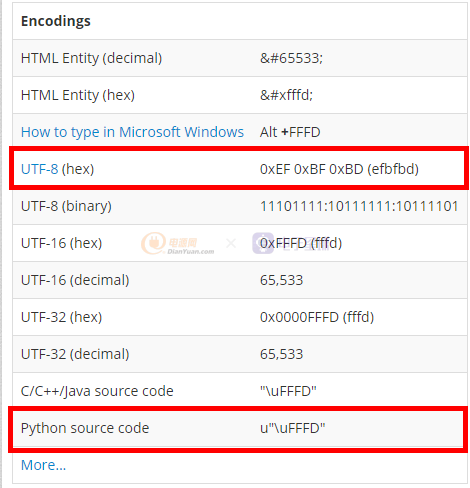
Unicode是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求,是一种字符编码。假如有一个字符,Unicode解析不了,Unicode官方用了一个占位符来表示这个字符,这就是:U+FFFD REPLACEMENT CHARACTER。即用"\uFFFD"代表这个字符,而"\uFFFD"的utf-8的编码是“'\xef\xbb\xbf”。如下图所示,以不同编码方式对"\uFFFD编码的结果,例如以utf-8编码的结果就是0xEFBFBD。
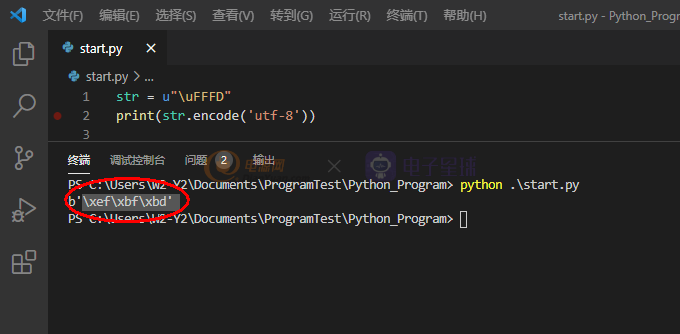
我们在Python中写两行代码测试一下
str = u"\uFFFD"
print(str.encode('utf-8'))str = u"\uFFFD"print(str.encode('utf-8'))
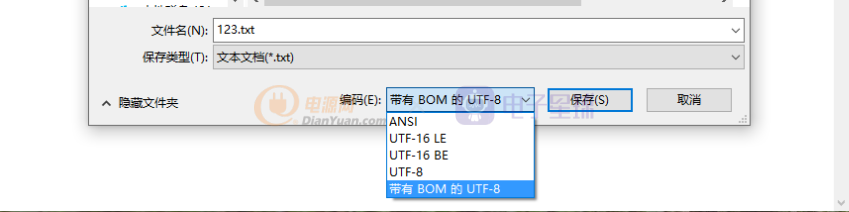
如果有两个未识别的字符那就是0xEFBFBDEFBFBD,在以GBK的环境显示,按照一个中文汉字占两个字节,最终就是:锟斤拷---锟(0xEFBF),斤(0xBDEF),拷(0xBFBD),这就是锟斤拷的由来。接下来在说“锘”,其实这个也是编码的问题。当我新建一个文本文档的时,内容为空,选择另存时有很多编码格式可选,如图,假如我选择了带有BOM的utf-8格式存储。
带有BOM的utf-8格式,其实就是在你的文件头部插入几个字节作为编码格式的标识。我们用Notepad++以十六进去打开这个文件,如下图:

文件内容是空的情况下已经有三个字节了,而且刚好前两个字节对应的中文刚好是“锘”。这种情况会经常会在网页上见到,原因就是使用了带有BOM的utf-8格式的文件。最后在总结一下,“烫烫烫”是由于栈未初始化引起的,“屯屯屯”是由于堆未初始化引起的,“锟斤拷”是由于Unicode未能识别字符而引起的,“锘”是由于文件类型是带有BOM的utf-8引起的。