

本文转自徐飞翔的“【动作识别相关,第一篇】skeleton骨骼点数据类型介绍”
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
1. 骨骼点数据1.1 骨骼点数据和其获得方法骨骼点数据是一种landmark类型的数据,指的是用关键点去描述整个人体的动作,我们可以称之为动作描述的pose信息,因此对这类数据的估计在文献中一般也称为姿态估计(Pose Estimation),效果如下图Fig1和Fig2所示:
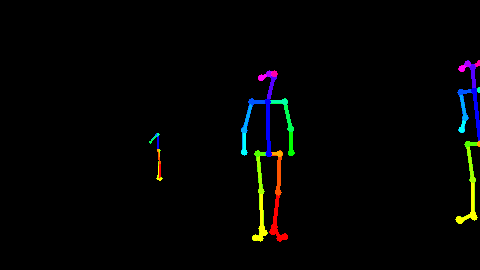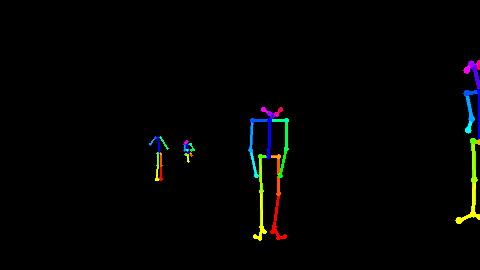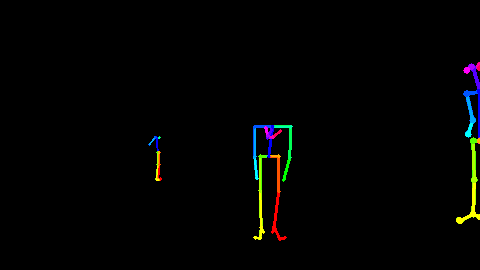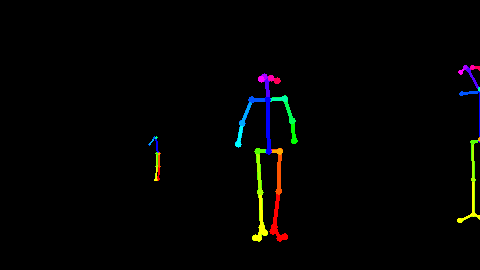
Fig 1. 利用Openpose[2]对RGB视频估计出来的骨骼点数据。

Fig 2. 利用Kinect v2.0[1]得到的骨骼点排序。
根据[3]中的研究,对于一个人体动作而言,可以通过10 ∼ 12 10 \sim 1210∼12个人体关节点有效地表达其动作内容1。为了获取到这种pose信息,按照使用器械不同或者原始模态不同,目前一般来说通过三种手段,分别是:
MoCap[4]全称为Motion Capture,是一种让表演者全身主要关节点穿戴好传感器之后,将传感器信息汇集到计算机中进行处理后,得到人体的关节点数据的一种系统。其得到的数据一般来说都是3D数据,既是有着关节点的(x,y,z)坐标的。

Fig 3. MoCap系统的示例,表演者需要全身穿戴传感器。
随着深度摄像头的发展,通过结构光或者ToF技术,我们现在已经可以用传感器对物体的深度信息进行描述了,这点是传统的RGB摄像头所难以解决的,效果如下图所示:

Fig 4. 用Kinect捕获的深度信息,越深的颜色表示距离离摄像头越远,越浅代表越近。
基于这种技术,我们可以描述物体到摄像头的远近距离了,结合彩色摄像头提供的色彩信息,就可以对物体进行更为精确的描述。基于深度图和彩色图像,一些公司开发了可以对其进行骨骼点估计的算法[5],典型的产品如Kinect和RealSense。这些产品因为是基于图像进行处理的,不能观测到物体被遮挡的一面,因此这样估计出来的结果其实不是 完美的3D信息 ,其被遮挡部分或多或少都是 “估计,猜” 出来的,因此看成是 2.5D 的信息。尽管如此,大多数这类产品都提供(x,y,z)等对关节点的估计。
尽管深度摄像头比起MoCap传感器来说的确便宜很多了,但是价格也还不够亲民,因此就产生了一类研究是关于如何仅仅依靠RGB图像对人体进行姿态估计,这个姿态估计可以是2D信息的[8],有些研究甚至是关于3D信息的[7],如Fig 5所示。
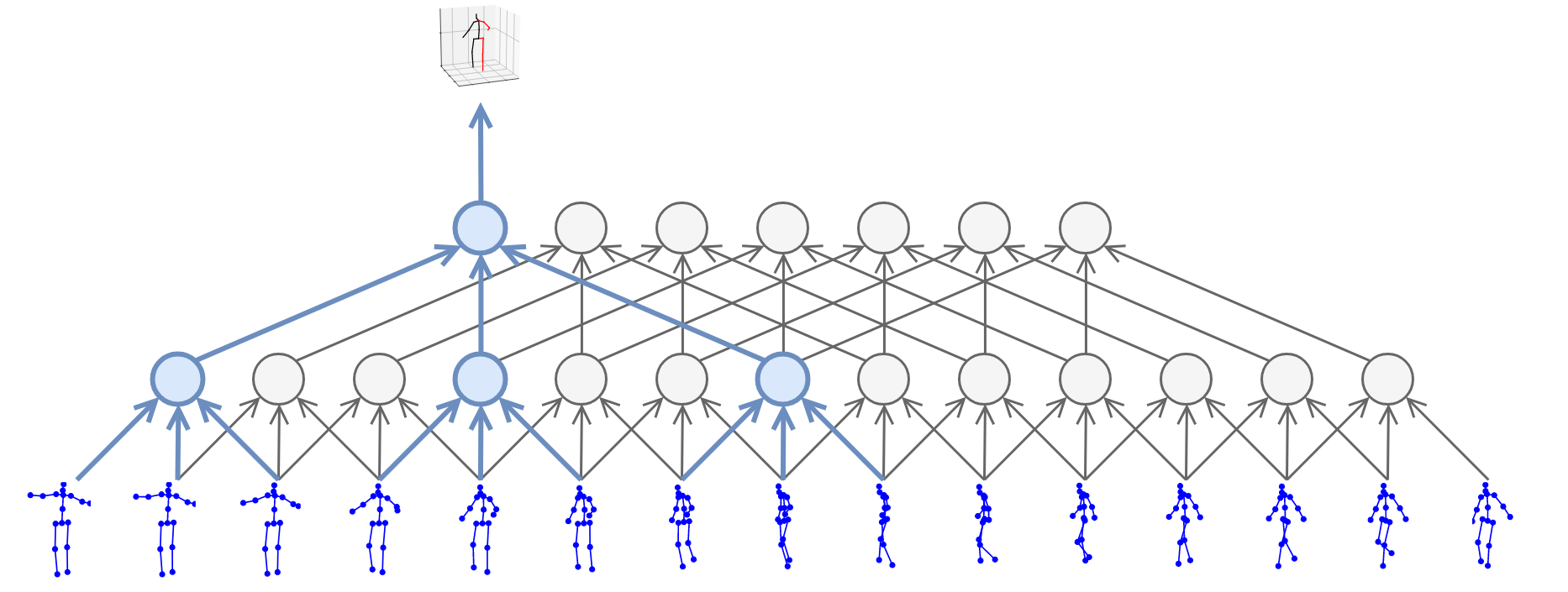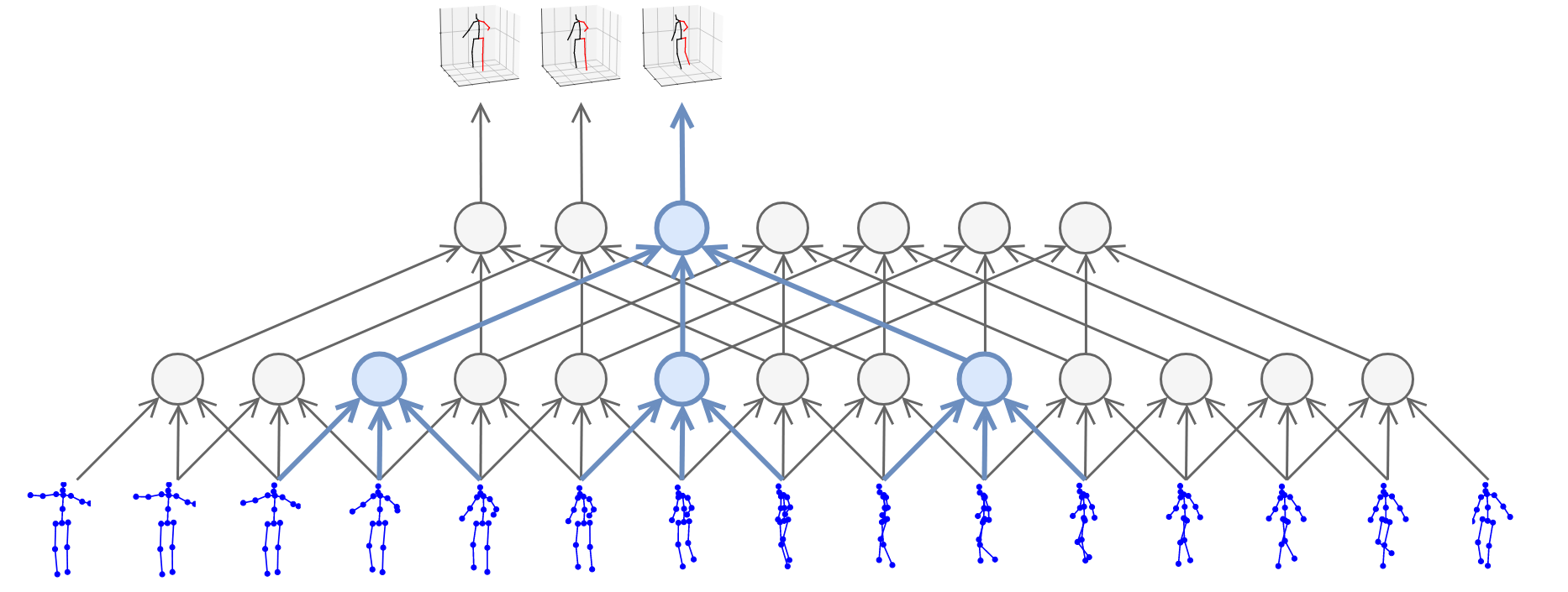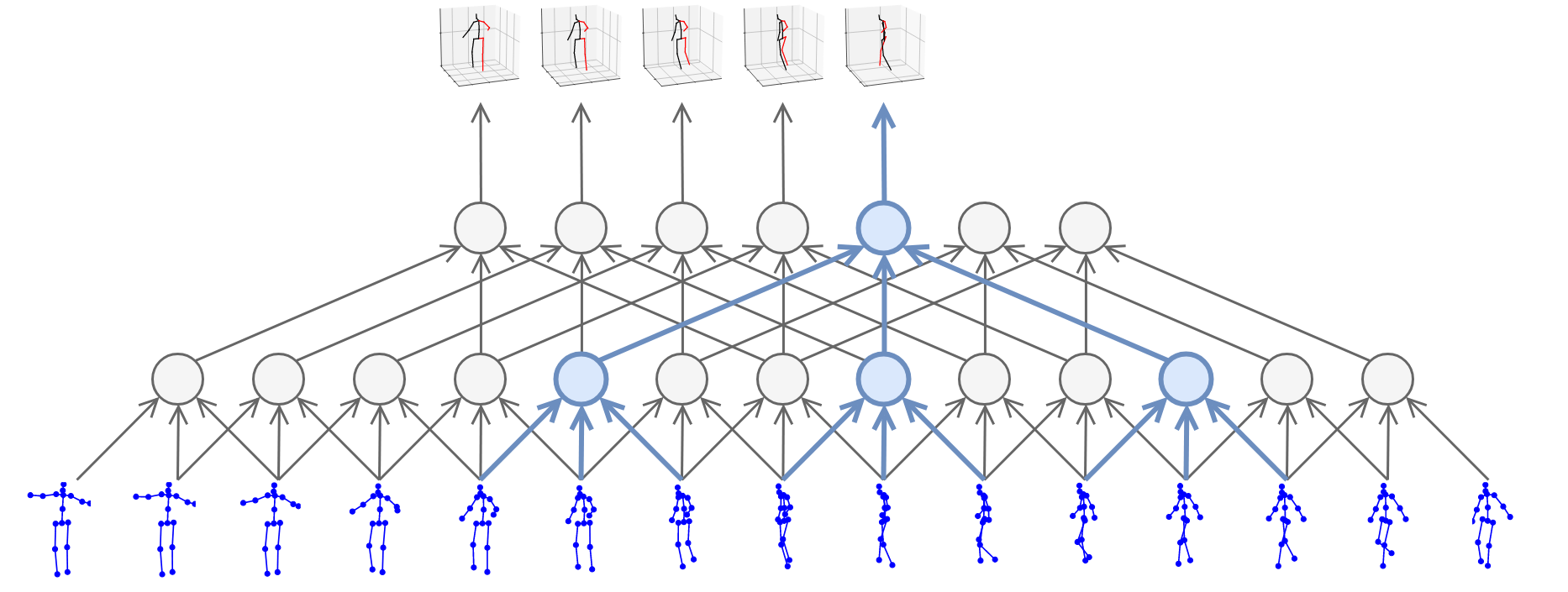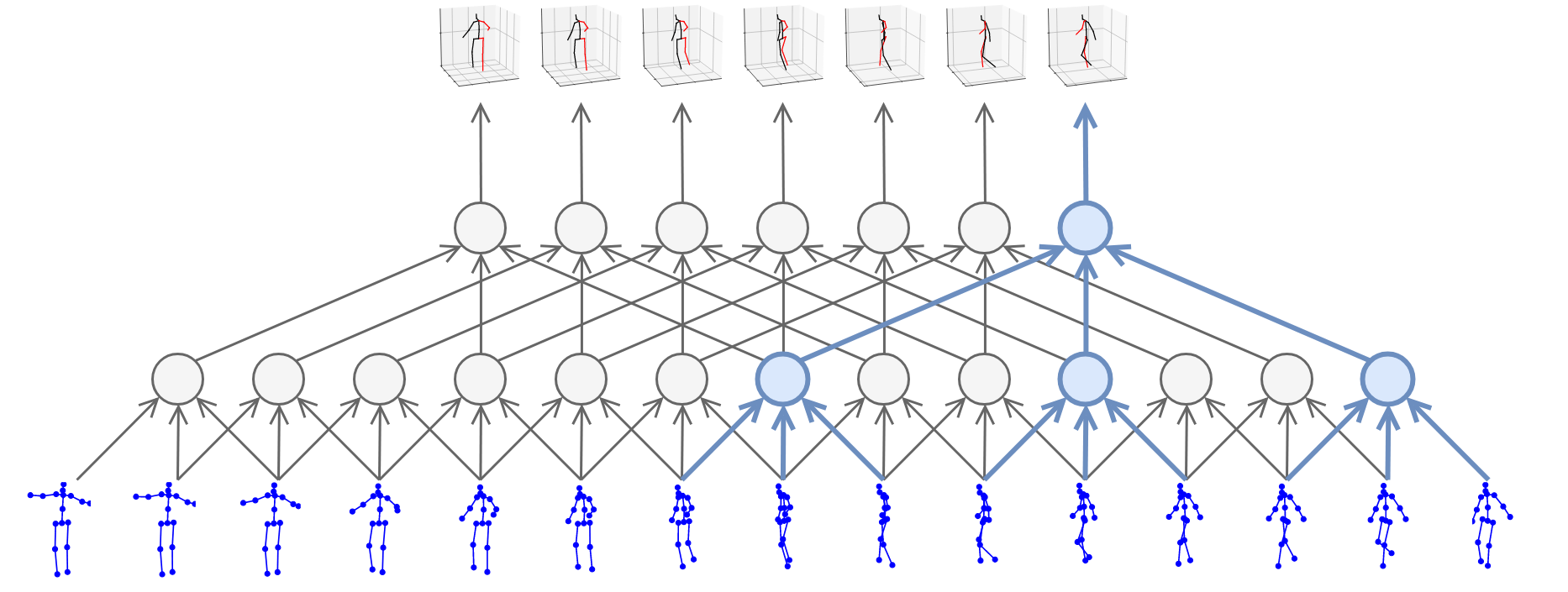
Fig 5. 利用RGB模态信息进行3D关节点的姿态估计。
目前,基于RGB的姿态估计基本上都是对遮挡部分鲁棒性不够,有部分工作[9-10]是考虑了对其进行遮挡部分的恢复的,但是似乎普遍对遮挡部分的效果都不是特别好,目前开源的最好结果似乎就是OpenPose了。(不是很了解姿态估计的进展,希望研究此的朋友给予指点)。
1.2 骨骼点数据的优劣
根据我们在1.1节讨论的,我们总结下这几类由不同手段得到的骨骼点数据的优劣点:
1.基于身体佩戴传感器的手段
优点:姿态估计结果准确,不存在因为身体遮挡导致的估计失败问题,鲁棒性高。
缺点:价格昂贵,不方便日常使用。
2.基于深度摄像头和彩色摄像头的手段
优点:方便使用,价格较为低廉,准确率较高。
缺点:对遮挡部分同样无能为力,只能通过时序上的上下文信息对某帧的遮挡部分进行推测,经常造成遮挡部分估计失败。
3.基于RGB视频的姿态估计
优点:价格最为低廉,一般摄像头就可以部署,可以大规模使用。
缺点:缺少了深度信息,导致对光照等信息比较敏感,同样无法克服遮挡部分的影响,准确率不如基于深度和彩色摄像头联合使用的效果。
从信息的角度来说,对比RGB视频信息,骨骼点信息极为紧凑,冗余量少,但是同样的,总体信息量也不如RGB模态的高,比如对于某些和物体交互的动作,光用骨骼点信息就很难完全描述。而且,因为其冗余量少,只要存在噪声,比如遮挡部分的推断噪声或者姿态估计算法不稳定导致的噪声,就会造成原信息的较大干扰,影响后续的识别或者其他任务的进行。如下图Fig 6和Fig 7所示,基于第二种和第三种方法的姿态估计通常对遮挡部分鲁棒性都不佳。

Fig 6. 用OpenPose对遮挡动作进行姿态估计,可以看到左手因为被遮挡而没有估计出来。

Fig 7. 用Kinect对遮挡动作进行姿态估计,左手部分被遮挡,但是Kinect还是对时序上的上下文进行了估计,但是这种估计常常效果不佳,容易引入估计噪声。
不过目前来说,基于骨骼点信息的应用因为其对于光照鲁棒性较强,对动作的表达能力强等特点,已经越来越受到了研究者的青睐。
Reference
[1]. Understanding Kinect V2 Joints and Coordinate System [需要特殊的上网姿势,你懂得]
[2]. OpenPose Github Project Page
[3]. Johansson G. Visual perception of biological motion and a model for its analysis[J]. Perception & psychophysics, 1973, 14(2): 201-211.
[4]. Rogez G, Schmid C. Mocap-guided data augmentation for 3d pose estimation in the wild[C]//Advances in Neural Information Processing Systems. 2016: 3108-3116.
[5]. Shotton J, Fitzgibbon A, Cook M, et al. Real-time human pose recognition in parts from single depth images[C]//Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on. Ieee, 2011: 1297-1304.
[6]. Kinect Introduction from Wikipedia
[7]. Pavllo D, Feichtenhofer C, Grangier D, et al. 3D human pose estimation in video with temporal convolutions and semi-supervised training[J]. arXiv preprint arXiv:1811.11742, 2018.
[8]. Cao Z, Simon T, Wei S E, et al. Realtime multi-person 2d pose estimation using part affinity fields[J]. arXiv preprint arXiv:1611.08050, 2016.
[9]. Sárándi I, Linder T, Arras K O, et al. How robust is 3D human pose estimation to occlusion?[J]. arXiv preprint arXiv:1808.09316, 2018.
[10]. Guo X, Dai Y. Occluded Joints Recovery in 3D Human Pose Estimation based on Distance Matrix[C]//2018 24th International Conference on Pattern Recognition (ICPR). IEEE, 2018: 1325-1330.